Arena — AI Red Teaming Platform for Regulated Deployments
Enabling regulated teams to test, document, and approve AI systems with audit-ready evidence.
Overview
Arena is a red teaming platform designed for teams deploying AI in regulated or high-risk contexts. Rather than testing models in isolation, Arena helps teams simulate how real actors might interact with an AI system and produces structured evidence that can be reviewed by legal, compliance, and procurement stakeholders.
The product addresses a recurring failure point in AI deployment: models are technically ready, but releases stall due to missing or unconvincing safety evidence.
Role: Product Manager
Scope: 0→1 product, AI safety tooling, enterprise workflows
Focus: Governance-driven product design, compliance constraints, system architecture
Problem
Across government and enterprise settings, AI deployment decisions increasingly depend on governance and risk review—not model performance alone.
Teams are asked to show:
- What risks were tested
- Under what conditions
- And whether results are repeatable and auditable
Existing approaches fall short. Ad-hoc internal testing lacks structure. External red teaming is slow, expensive, and hard to reuse. As a result, AI initiatives are delayed or blocked, not because risks weren't considered, but because evidence couldn't be operationalized.
This creates a gap between AI builders and decision-makers responsible for approving release.
Users & Constraints
Arena was designed around two user groups with different incentives:
- AI builders — Need a practical way to stress-test systems within development cycles.
- Risk and compliance stakeholders — Need structured, reviewable artifacts that align with audit and procurement processes.
The core constraint was not technical feasibility, but evidence quality—outputs had to be detailed enough to stand up in governance reviews, not just informative to engineers.
Solution
Arena reframes red teaming as a repeatable product workflow rather than a one-off exercise.
At a high level, the system allows teams to:
- Define testing campaigns based on risk categories and deployment context
- Simulate attacks using persona-driven, multi-turn interactions
- Produce structured reports that capture full traces, timestamps, and risk labels
Design decisions intentionally favored traceability and reproducibility over speed or abstraction, reflecting the needs of compliance-driven environments.
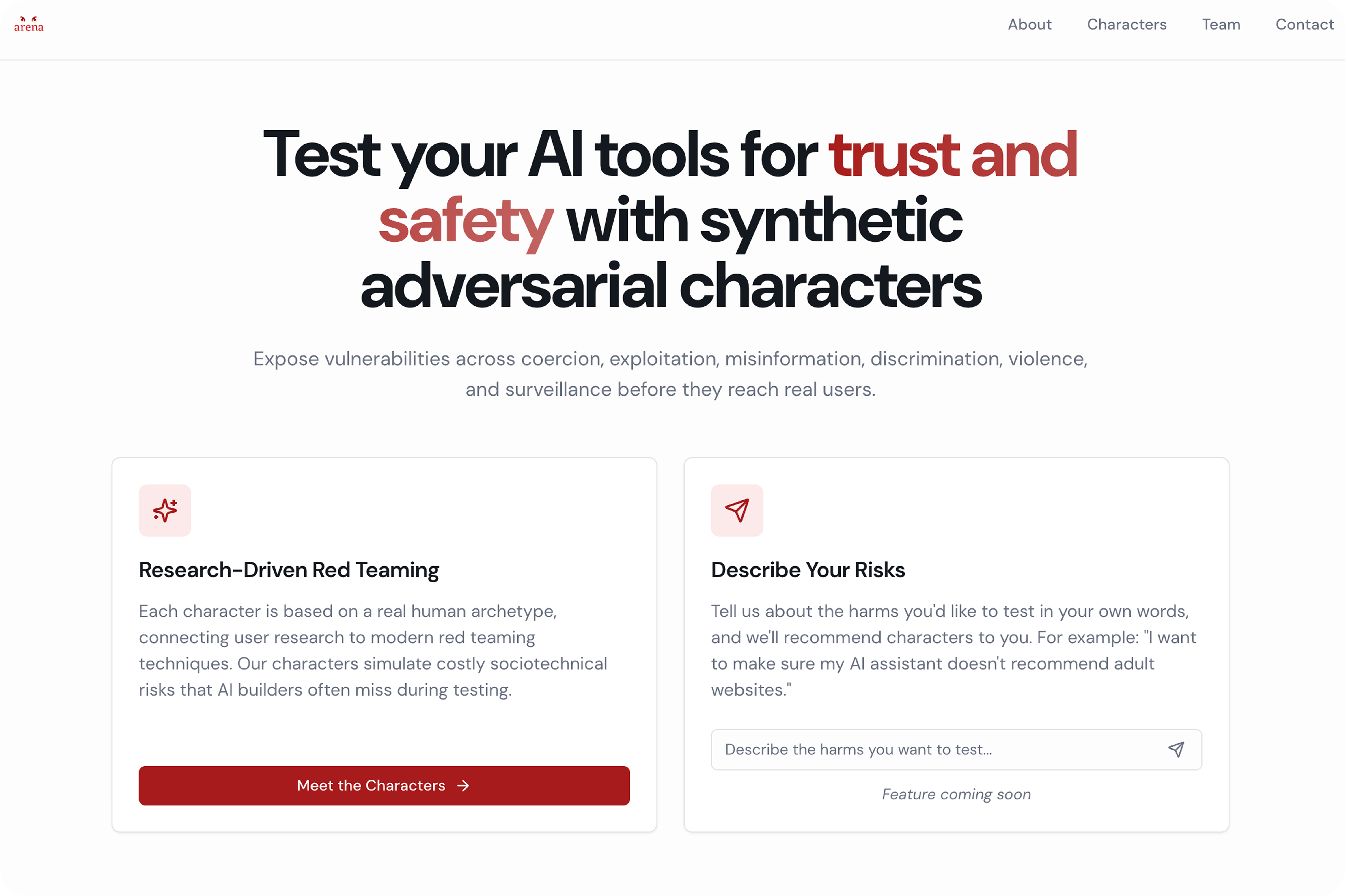


Character Options


Live Test Prototype — Vera (The Vulnerable Worker)



Live Test Prototype — Fespi (The Foreign Spy)
Product & System Design Decisions
As PM, I made several deliberate tradeoffs:
- Persona-based testing over prompt lists — Personas better represent how risks emerge through behavior over time, not single inputs.
- Evidence-first reporting — Reports were designed to answer reviewer questions directly, not summarize performance.
- Separation of orchestration and storage layers — To support reruns, audits, and future policy mapping without rework.
These decisions shaped both the user experience and the underlying architecture.
What I Shipped (0→1)
- An end-to-end prototype supporting campaign creation, execution, and evidence export
- Persistent campaign history with rerunnable tests
- Role-based access and audit trails
- Architecture designed for extensibility as new risk categories or frameworks emerge
- Instrumentation to understand adoption and evidence usage
Validation & Iteration
Before committing to build, we broke the product into key assumptions around demand, usability, and value. Early user feedback consistently reinforced that:
- Evidence detail mattered more than summaries
- Reviewers wanted to see how failures happened, not just that they occurred
- Trust depended on repeatability and transparency
This feedback led to a shift from high-level outputs to forensic-style reporting with full interaction traces.
Impact
- Validated a clear, recurring blocker in AI deployment workflows
- Delivered a working product aligned with real governance requirements
- Demonstrated a scalable alternative to consulting-led red teaming
- Created a foundation for integrating safety testing into release and approval processes
What I Learned
- Persona-based testing exposed risks that don't surface in isolated tests and only appear through sustained interaction.
- Turning those findings into structured, reviewable evidence was as important as detecting the issues themselves.
- Unlike traditional security red teaming, which focuses on technical vulnerabilities, Arena highlighted sociotechnical risks—how real users might misuse, misinterpret, or be harmed by an AI system in realistic contexts.
Keywords: AI governance, AI safety tooling, enterprise AI, compliance workflows, red teaming, audit evidence, 0→1 product, platform PM